

 Editing engine
Editing engine
The @ckeditor/ckeditor5-engine package is by far the biggest package of all. Therefore, this guide will only scratch the surface here by introducing the main architecture layers and concepts. More detailed guides will follow.
We recommend using the official CKEditor 5 inspector for development and debugging. It will give you tons of useful information about the state of the editor such as internal data structures, selection, commands, and many more.
# Overview
The editing engine implements an MVC architecture. The shape of it is not enforced by the engine itself but in most implementations it can be described by this diagram:
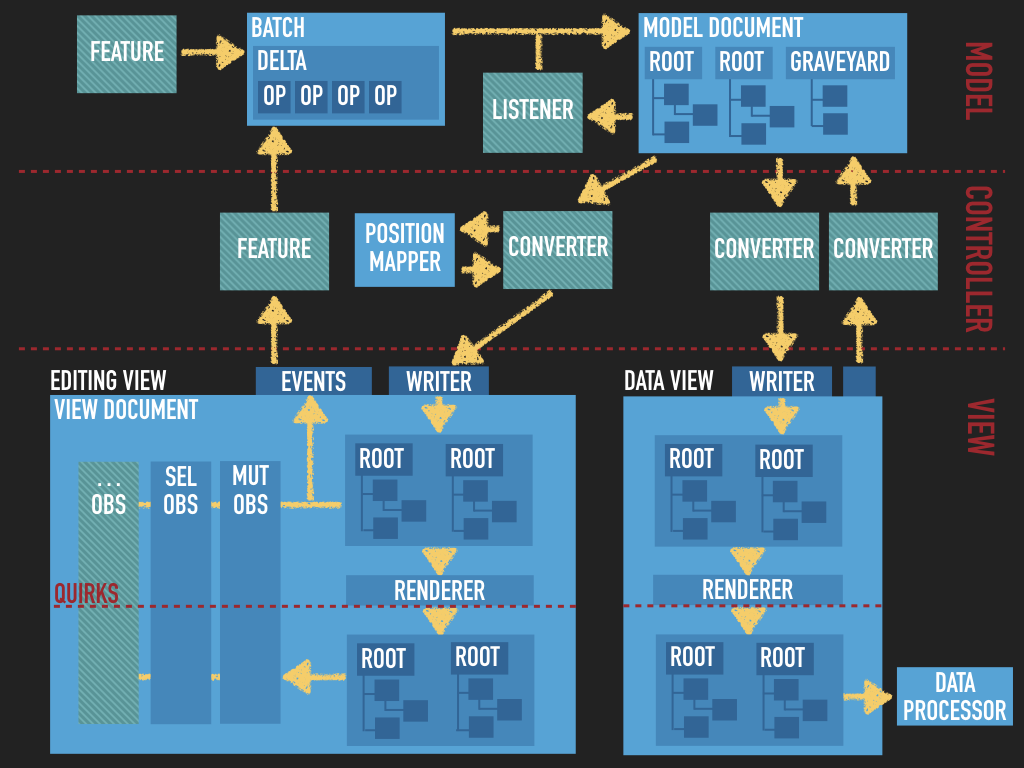
What you can see, are three layers: model, controller and view. There is one model document which is converted into separate views — the editing view and the data view. These two views represent, respectively, the content that the user is editing (the DOM structure that you see in the browser) and the editor input and output data (in a format that the plugged data processor understands). Both views feature virtual DOM structures (custom, DOM-like structures) on which converters and features work and which are then rendered to the DOM.
The green blocks are the code introduced by editor features (plugins). These features control what changes are made to the model, how they are converted to the view and how the model needs to be changed based on fired events (the view’s and model’s ones).
Let’s now talk about each layer separately.
# Model
The model is implemented by a DOM-like tree structure of elements and text nodes. Unlike in the actual DOM, in the model, both elements and text nodes can have attributes.
Like in the DOM, the model structure is contained within a document that contains root elements (the model, as well as the view, may have multiple roots). The document also holds its selection and the history of its changes.
Finally, the document, its schema and document markers are properties of the Model. An instance of the Model class is available in the editor.model property. The model, besides holding the properties described above, provides the API for changing the document and its markers, too.
# Changing the model
All changes in the document structure, of the document’s selection and even the creation of elements, can only be done by using the model writer. Its instance is available in change() and enqueueChange() blocks.
All changes done within a single change() block are combined into one undo step (they are added to a single batch). When nesting change() blocks, all changes are added to the outermost change() block’s batch. For example, the code below will create a single undo step:
All changes made to the document structure are done by applying operations. The concept of operations comes from Operational Transformation (in short: OT), a technology enabling collaboration functionality. Since OT requires a system to be able to transform every operation by every other one (to figure out the result of concurrently applied operations), the set of operations needs to be small. CKEditor 5 features a non-linear model (normally, OT implementations use flat, array-like models while CKEditor 5 uses a tree structure), hence the set of potential semantic changes is more complex. Operations are grouped in batches. A batch may be understood as a single undo step.
# Text attributes
Text styles such as “bold” and “italic” are kept in the model not as elements but as text attributes (think — like element attributes). The following DOM structure:
would translate to the following model structure:
Such representation of inline text styling allows to significantly reduce the complexity of algorithms operating on the model. For instance, if you have the following DOM structure:
and you have a selection before the letter "b" ("Foo ^bar"), is this position inside or outside <strong>? If you use native DOM Selection, you may get both positions — one anchored in <p> and the other anchored in <strong>. In CKEditor 5 this position translates exactly to "Foo ^bar".
# Selection attributes
OK, but how to let CKEditor 5 know that I want the selection to “be bold” in the case described above? This is important information because it affects whether or not the typed text will be bold, too.
To handle that, the selection also has attributes. If the selection is placed in "Foo ^bar" and it has the attribute bold=true, you know that the user will type bold text.
# Indexes and offsets
However, it has just been said that inside <paragraph> there are two text nodes: "Foo " and "bar". If you know how native DOM Ranges work you might thus ask: “But if the selection is at the boundary of two text nodes, is it anchored in the left one, the right one, or in the containing element?”
This is, indeed, another problem with DOM APIs. Not only can positions outside and inside some element be identical visually but also they can be anchored inside or outside a text node (if the position is at a text node boundary). This all creates extreme complications when implementing editing algorithms.
To avoid such troubles, and to make collaborative editing possible for real, CKEditor 5 uses the concepts of indexes and offsets. Indexes relate to nodes (elements and text nodes) while offsets relate to positions. For example, in the following structure:
The "Foo " text node is at index 0 in its parent, <imageInline></imageInline> is at index 1 and "bar" is at index 2.
On the other hand, offset x in <paragraph> translates to:
| Offset | Position | Node |
|---|---|---|
0 |
<paragraph>^Foo <imageInline></imageInline>bar</paragraph> |
"Foo " |
1 |
<paragraph>F^oo <imageInline></imageInline>bar</paragraph> |
"Foo " |
4 |
<paragraph>Foo ^<imageInline></imageInline>bar</paragraph> |
<imageInline> |
6 |
<paragraph>Foo <imageInline></imageInline>b^ar</paragraph> |
"bar" |
# Positions, ranges and selections
The engine also defines three levels of classes that operate on offsets:
- A
Positioninstance contains an array of offsets (which is called a “path”). See the examples in thePosition#pathAPI documentation to better understand how paths work. - A
Rangecontains two positions: start and end ones. - Finally, there is a
Selectionwhich contains one or more ranges, attributes, and has a direction (whether it was done from left to right or right to left). You can make as many instances of it as you need and you can freely modify it whenever you want. Additionally, there is a singleDocumentSelection. It represents the document’s selection and can only be changed through the model writer. It is automatically updated when the document’s structure is changed.
# Markers
Markers are a special type of ranges.
- They are managed by
MarkerCollection. - They can only be created and changed through the model writer.
- They can be synchronized over the network with other collaborating clients.
- They are automatically updated when the document’s structure is changed.
- They can be converted to the editing view to show them in the editor (as highlights or elements).
- They can be converted to the data view to store them with the document data.
- They can be loaded with the document data.
Markers are perfect for storing and maintaining additional data related to portions of the document such as comments or selections of other users.
# Schema
The model’s schema defines several aspects of how the model should look:
- Where a node is allowed or disallowed (e.g.
paragraphis allowed in$root, but not inheading1). - What attributes are allowed for a certain node (e.g.
imagecan have thesrcandaltattributes). - Additional semantics of model nodes (e.g.
imageis of the “object” type and paragraph of the “block” type).
This information is then used by the features and the engine to make decisions on how to process the model. For instance, the information from the schema will affect:
- What happens with the pasted content and what is filtered out (note: in case of pasting the other important mechanism is the conversion. HTML elements and attributes which are not upcasted by any of the registered converters are filtered out before they even become model nodes, so the schema is not applied to them; the conversion will be covered later in this guide).
- To which elements the heading feature can be applied (which blocks can be turned to headings and which elements are blocks in the first place).
- Which elements can be wrapped with a block quote.
- Whether the bold button is enabled when the selection is in a heading (and whether the text in this heading can be bolded).
- Where the selection can be placed (which is — only in text nodes and on object elements).
- etc.
The schema is, by default, configured by editor plugins. It is recommended that every editor feature comes with rules that enable and preconfigure it in the editor. This will make sure that the plugin user can enable it without worrying to re-configure their schema.
Currently, there is no straightforward way to override the schema preconfigured by features. If you want to override the default settings when initializing the editor, the best solution is to replace editor.model.schema with a new instance of it. This, however, requires rebuilding the editor.
The instance of the schema is available in editor.model.schema. Read an extensive guide about using the schema API in the Schema deep dive guide.
# View
Let’s again take a look at the editing engine’s architecture:
So far, we talked about the topmost layer of this diagram — the model. The role of the model layer is to create an abstraction over the data. Its format was designed to allow storing and modifying the data in the most convenient way, while enabling implementation of complex features. Most features operate on the model (read from it and change it).
The view, on the other hand, is an abstract representation of the DOM structure which should be presented to the user (for editing) and which should (in most cases) represent the editor’s input and output (i.e. the data returned by editor.getData(), the data set by editor.setData(), pasted content, etc.).
What this means is that:
- The view is yet another custom structure.
- It resembles the DOM. While the model’s tree structure only slightly resembled the DOM (e.g. by introducing text attributes), the view is much closer to the DOM. In other words, it is a virtual DOM.
- There are two “pipelines”: the editing pipeline (also called the “editing view”) and the data pipeline (the “data view”). Treat them as two separate views of one model. The editing pipeline renders and handles the DOM that the user sees and can edit. The data pipeline is used when you call
editor.getData(),editor.setData()or paste content into the editor. - The views are rendered to the DOM by the
Rendererwhich handles all the quirks required to tame thecontentEditableused in the editing pipeline.
The fact that there are two views is visible in the API:
Technically, the data pipeline does not have a document and a view controller. It operates on detached view structures, created for the purposes of processing data.
It is much simpler than the editing pipeline and in the following part of this section we will be talking about the editing view.
Check out the EditingController's and DataController's API for more details.
# Element types and custom data
The structure of the view resembles the structure in the DOM very closely. The semantics of HTML is defined in its specification. The view structure comes “DTD-free”, so in order to provide additional information and to better express the semantics of the content, the view structure implements 6 element types (ContainerElement, AttributeElement, EmptyElement, RawElement, UIElement, and EditableElement) and so called “custom properties” (i.e. custom element properties which are not rendered). This additional information provided by the editor features is then used by the Renderer and converters.
The element types can be defined as follows:
- Container element – The elements that build the structure of the content. Used for block elements such as
<p>,<h1>,<blockQuote>,<li>, etc. - Attribute element – The elements that cannot hold container elements inside them. Most model text attributes are converted to view attribute elements. They are used mostly for inline styling elements such as
<strong>,<i>,<a>,<code>. Similar attribute elements are flattened by the view writer, so e.g.<a href="..."><a class="bar">x</a></a>would automatically be optimized to<a href="..." class="bar">x</a>. - Empty element – The elements that must not have any child nodes, for example
<img>. - UI element – The elements that are not a part of the “data” but need to be “inlined” in the content. They are ignored by the selection (it jumps over them) and the view writer in general. The contents of these elements and events coming from them are filtered out, too.
- Raw element – The elements that work as data containers (“wrappers”, “sandboxes”) but their children are transparent to the editor. Useful when non-standard data must be rendered but the editor should not be concerned what it is and how it works. Users cannot put the selection inside a raw element, split it into smaller chunks or directly modify its content.
- Editable element – The elements used as “nested editables” of non-editable fragments of the content, for example a caption in the image widget, where the
<figure>wrapping the image is not editable (it is a widget) and the<figcaption>inside it is an editable element.
Additionally, you can define custom properties which may be used to store information like:
- Whether an element is a widget (added by
toWidget()). - How an element should be marked when a marker highlights it.
- Whether an element belongs to a certain feature — if it is a link, progress bar, caption, etc.
# Non-semantic views
Not all view trees need to (and can) be build with semantic element types. View structures generated straight from input data (e.g. pasted HTML or with editor.setData()) consists only of base element instances. Those view structures are (usually) converted to model structures and then converted back to view structures for editing or data retrieval purposes, at which point they become semantic views again.
The additional information conveyed in the semantic views and special types of operations that feature developers want to perform on those tree (compared to simple tree operations on non-semantic views) means that both structures need to be modified by different tools.
We will explain the conversion later in this guide. For now, it is only important for you to know that there are semantic views for rendering and data retrieval purposes and non-semantic views for data input.
# Changing the view
Do not change the view manually, unless you really know what you are doing. If the view needs to be changed, in most cases, it means that the model should be changed first. Then the changes you apply to the model are converted (conversion is covered below) to the view by specific converters.
The view may need to be changed manually if the cause of such change is not represented in the model. For example, the model does not store information about the focus, which is a property of the view. When the focus changes, and you want to represent that in some element’s class, you need to change that class manually.
For that, just like in the model, you should use the change() block (of the view) in which you will have access to the view downcast writer.
There are two view writers:
DowncastWriter— available in thechange()blocks, used during downcasting the model to the view. It operates on a “semantic view” so a view structure which differentiates between different types of elements (see Element types and custom data).UpcastWriter— a writer to be used when pre-processing the “input” data (e.g. pasted content) which happens usually before the conversion (upcasting) to the model. It operates on “non-semantic views”.
# Positions
Just like in the model, there are 3 levels of classes in the view that describe points in the view structure: positions, ranges and selections. A position is a single point in the document. A range consists of two positions (start and end). A selection consists of one or more ranges and has a direction (whether it was done from left to right or from right to left).
A view range is very similar to its DOM counterpart as view positions are represented by a parent and an offset in that parent. This means that, unlike model offsets, view offsets describe:
- points between child nodes of the position’s parent if it is an element,
- or points between the character of a text node if position’s parent is a text node.
Therefore, you can say that view offsets work more like model indexes than model offsets.
| Parent | Offset | Position |
|---|---|---|
<p> |
0 |
<p>^Foo<img></img>bar</p> |
<p> |
1 |
<p>Foo^<img></img>bar</p> |
<p> |
2 |
<p>Foo<img></img>^bar</p> |
<img> |
0 |
<p>Foo<img>^</img>bar</p> |
Foo |
1 |
<p>F^oo<img></img>bar</p> |
Foo |
3 |
<p>Foo^<img></img>bar</p> |
As you can see, two of these positions represent what you can consider the same point in the document:
{ parent: paragraphElement, offset: 1 }{ parent: fooTextNode, offset: 3 }
Some browsers (Safari, Chrome and Opera) consider them identical, too (when used in a selection) and often normalize the first position (anchored in an element) to a position anchored in a text node (the second position). Do not be surprised that the view selection is not directly where you would like it to be. The good news is that the CKEditor 5 renderer can tell that two positions are identical and avoids re-rendering the DOM selection unnecessarily.
Sometimes you may find in the documentation that positions are marked in HTML with the {} and [] characters. The difference between them is that the former indicates positions anchored in text nodes and the latter in elements. So, for example, the following example:
describes a range which starts in the text node Foo at offset 0 and ends in the <p> element at offset 1.
The far-from-convenient representation of DOM positions is yet one more reason to think about and work with model positions.
# Observers
In order to create a safer and more useful abstraction over native DOM events, the view implements the concept of observers. It improves the testability of the editor as well as simplifies the listeners added by editor features by transforming the native events into a more useful form.
An observer listens to one or more DOM events, does preliminary processing of this event and then fires a custom event on the view document. An observer not only creates an abstraction on the event itself but also on its data. Ideally, an event’s consumer should not have any access to the native DOM.
By default, the view adds the following observers:
MutationObserverSelectionObserverFocusObserverKeyObserverFakeSelectionObserverCompositionObserverArrowKeysObserver
Additionally, some features add their own observers. For instance, the clipboard feature adds ClipboardObserver.
For a complete list of events fired by observers check the Document's list of events.
You can add your own observer (which should be a subclass of Observer) by using the view.addObserver() method. Check the code of existing observers to learn how to write them: https://github.com/ckeditor/ckeditor5-engine/tree/master/src/view/observer.
Since all events are by default fired on Document, it is recommended that third party packages prefix their events with an identifier of the project to avoid name collisions. For example, MyApp’s features should fire myApp:keydown instead of keydown.
# Conversion
So far, we talked about the model and the view as about two completely independent subsystems. It is time to connect them. The three main situations in which these two layers meet are:
| Conversion name | Description |
|---|---|
| Data upcasting | Loading the data to the editor. First, the data (e.g. an HTML string) is processed by a DataProcessor to a view DocumentFragment. Then, this view document fragment is converted to a model document fragment. Finally, the model document’s root is filled with this content. |
| Data downcasting | Retrieving the data from the editor. First, the content of the model’s root is converted to a view document fragment. Then this view document fragment is processed by a data processor to the target data format. |
| Editing downcasting | Rendering the editor content to the user for editing. This process takes place for the entire time when the editor is initialized. First, the model’s root is converted to the view’s root once data upcasting finishes. After that this view root is rendered to the user in the editor’s contentEditable DOM element (also called “the editable element”). Then, every time the model changes, those changes are converted to changes in the view. Finally, the view can be re-rendered to the DOM if needed (if the DOM differs from the view). |
Let’s take a look at the diagram of the engine’s MVC architecture and see where each of the conversion processes happen in it:
# Data pipeline
Data upcasting is a process which starts in the bottom right corner of the diagram (in the view layer), passes from the data view, through a converter (green box) in the controller layer to the model document in the top right-hand corner. As you can see, it goes from the bottom to the top, hence “upcasting”. Also, it is handled by the data pipeline (the right branch of the diagram), hence “data upcasting”. Note: Data upcasting is also used to process pasted content (which is similar to loading data).
Data downcasting is the opposite process to data upcasting. It starts in the top right-hand corner and goes down to the bottom right-hand corner. Again, the name of the conversion process matches the direction and the pipeline.
# Editing pipeline
Editing downcasting is a bit different process than the other two.
- It takes place in the “editing pipeline” (the left branch of the diagram).
- It does not have its counterpart — there is no editing upcasting because all user actions are handled by editor features by listening to view events, analyzing what happened and applying necessary changes to the model. Hence, this process does not involve conversion.
- Unlike
DataController(which handles the data pipeline),EditingControllermaintains a single instance of theDocumentview document’s for its entire life. Every change in the model is converted to changes in that view so changes in that view can then be rendered to the DOM (if needed — i.e. if the DOM actually differs from the view at this stage).
# More information
A more in-depth introduction with examples can be found in the dedicated conversion guide.
For additional information, you can also check out the Implementing a block widget and Implementing an inline widget tutorials.
# Read next
Once you have learnt how to implement editing features, it is time to add a UI for them. You can read about the CKEditor 5 standard UI framework and UI library in the UI library guide.
Every day, we work hard to keep our documentation complete. Have you spotted an outdated information? Is something missing? Please report it via our issue tracker.